Visualizing the State of the Amsterdam Housing Market
20 June 2021
For this post, I decided to hide the code chunks by default to improve legibility. You can click on Show code to expand the code.
Introduction
I’m at the age where a lot of my peers start thinking about buying a home. It is a major conversation topic around the office, and these conversations are not often filled with optimism and excitement. Oslo is a notoriously expensive city to live in, and the housing market is very tough.
Of all the worrying events in 2020, millennials and Gen Z kids ranked financial instability as the second most common driver of stress, the most common being the welfare of their family (source). Today I want to dissect one of the possible causes of this economic anxiety: the housing market. Now, I’m not an economist nor a financial expert. Nonetheless, I believe I can leverage some of my knowledge of data wrangling and analysis to contribute a small piece to this topic. My insight into the Oslo housing market is fairly limited to so far and there’s many nuances I don’t fully understand yet, but I do think I have some relevant knowledge of the Dutch housing market. So today I’ll dive into some data on the Dutch market, and particularly the Amsterdam housing market. There’s countless stories about the Amsterdam housing market and how terrible it is for new buyers, similar to the Oslo housing market. However, in my opinion the Amsterdam housing market is already a few steps ahead of the Oslo market, and hopefully the Amsterdam market can offer some warnings about what the Oslo housing market might look like in a few years without some policy corrections.
This will be a fairly basic data analysis and visualization post, I can’t claim that this is an exhaustive list and that I didn’t miss some nuances, but I’ll give it . I collected some data from the Amsterdam Real Estate Association (Makelaars Vereniging Amsterdam; MVA) and statistics from the Central Bureau for Statistics (Centraal Bureau for de Statistiek; CBS). As usual, I’ll be using {tidyverse} a lot. I’ve also recently started using the {ggtext} package to manage the text elements in my plots, inspired by Cédric Scherer (@CedScherer). I’ll use the {gt} package to spice up some of the tables, and {patchwork} for arranging plots. I’ll use the {cbsodataR} to download data from the Central Bureau for Statistics (CBS).
Show code
library(tidyverse)
library(ggtext)
library(patchwork)
library(magrittr)
library(showtext)
library(gt)
font_add_google(name = "Nunito Sans", family = "nunito-sans")
showtext_auto()
theme_set(ggthemes::theme_economist(base_family = "nunito-sans") +
theme(
rect = element_rect(fill = "#EBEBEB", color = "transparent"),
plot.background = element_rect(
fill = "#EBEBEB",
color = "transparent"
),
panel.background = element_rect(
fill = "#EBEBEB",
color = "transparent"
),
plot.title = element_textbox(
margin = margin(0, 0, 5, 0, "pt")
),
plot.title.position = "plot",
plot.subtitle = element_textbox(
hjust = 0,
margin = margin(0, 0, 15, 0, "pt")
),
plot.caption = element_textbox(hjust = 1),
plot.caption.position = "plot",
axis.title.y = element_textbox(
orientation = "left-rotated", face = "bold",
margin = margin(0, 0, 5, 0, "pt")
),
axis.text.y = element_text(hjust = 1),
legend.position = "bottom",
legend.box = "vertical",
legend.text = element_text(size = 10)
))
Getting the data
The first piece of data I’ll use comes from the Amsterdam Real Estate Association. They publish quarterly data on a number of variables about the Amsterdam housing market (link), inclusing asking price, final price paid, number of properties put on the market, number of properties sold and a few more back to the first quarter of 2012. Obviously, these numbers all come in pdf-format, because the people writing quarterly reports apparently have a massive hatred towards people that want to analyze this data. I downloaded the reports, used the online tool PDFTables to convert them to Excel, and then stitched the tables together manually. Of course (remember the authors have a massive hatred towards us), the formatting of the numbers in the tables weren’t consistent between different quarterly reports, so I had to do some cleaning in R. I put each table in a separate sheet and then used functionality from the {readxl} package to load each table into a different variable and then do the cleaning per table. This was a bit cumbersome.
You can look at the code I used to load and merge the files. It’s a bit of a mess:
Show code
asking_price <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 2
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(where(is.double), ~ .x * 1e3),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "asking_price"
)
transaction_price <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 3
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "transaction_price"
)
price_per_m2 <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 4
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(where(is.double), ~ .x * 1e3),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "price_per_m2"
)
n_offered <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 5
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "n_offered"
)
n_sold <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 6
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "n_sold"
)
mortgage_months <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 7
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(
where(is.character),
~ parse_number(str_remove_all(.x, fixed(" ")))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "mortgage_months"
)
tightness_index <- readxl::read_xlsx("./data/MVA_kwartaalcijfers.xlsx",
sheet = 8
) |>
janitor::clean_names() |>
mutate(
type_woning = as_factor(type_woning),
across(
where(is.character),
~ parse_number(str_replace_all(.x, ",", "."))
)
) |>
pivot_longer(starts_with("x"),
names_to = "date", values_to = "tightness_index"
)
data_merged <- inner_join(asking_price, transaction_price) |>
inner_join(price_per_m2) |>
inner_join(n_offered) |>
inner_join(n_sold) |>
inner_join(mortgage_months) |>
inner_join(tightness_index) |>
mutate(
asking_price = ifelse(asking_price < 1e5,
asking_price * 1e3,
asking_price
),
transaction_price = ifelse(transaction_price < 1e5,
transaction_price * 1e3,
transaction_price
),
price_per_m2 = ifelse(price_per_m2 > 1e4,
price_per_m2 / 1e3,
price_per_m2
)
)
write_rds(data_merged, "./data/data_merged.rds")
Let’s have a look at the dataset.
Show code
data_merged <- read_rds("./data/data_merged.rds")
glimpse(data_merged)
Rows: 259
Columns: 9
$ type_woning <fct> Tussenwoning, Tussenwoning, Tussenwoning, Tussenwoni…
$ date <chr> "x1e_kw_2012", "x2e_kw_2012", "x3e_kw_2012", "x4e_kw…
$ asking_price <dbl> 298444, 269778, 241000, 270500, 354056, 305611, 3478…
$ transaction_price <dbl> 278911, 252278, 230111, 256667, 334472, 281528, 3230…
$ price_per_m2 <dbl> 2492, 2370, 2308, 2291, 2648, 2203, 2412, 2344, 3002…
$ n_offered <dbl> 655, 732, 717, 717, 676, 732, 715, 617, 534, 573, 51…
$ n_sold <dbl> 99, 119, 107, 153, 93, 93, 123, 148, 121, 178, 158, …
$ mortgage_months <dbl> 126, 103, 85, 125, 147, 113, 135, 85, 121, 57, 74, 6…
$ tightness_index <dbl> 19.8, 18.5, 20.1, 14.1, 21.8, 23.6, 17.4, 12.5, 13.3…
From this dataset, I want to create a few new variables. I want to create a date format from the quarterly date. Currently it’s in the format "x1e_kw_2012". We’ll extract the year and the quarter. Since there’s 4 quarters in the 12 months, we’ll multiply the quarter by 3 and then create a date format. We’ll also calculate the percentage difference between the asking price and the price paid, and the percentage difference between the houses offered and the houses sold. I’ll also translate the character string from Dutch to English using the case_when() function.
Show code
data <- data_merged |>
rename(type = type_woning) |>
mutate(
quarter = str_extract(date, pattern = "x(.*?)e"),
quarter = parse_number(quarter),
year = str_extract(date, pattern = "kw_(.*)"),
year = parse_number(year),
date = as.Date(str_glue("{year}-{(quarter * 3)}-01")),
diff_ask_paid = transaction_price - asking_price,
diff_ask_paid_perc = diff_ask_paid / asking_price,
diff_offered_sold = n_offered - n_sold,
diff_offered_sold_perc = diff_offered_sold / n_offered,
perc_sold = n_sold / n_offered,
type = case_when(
str_detect(type, "Totaal") ~ "Total",
str_detect(type, "<= 1970") ~ "Apartments (pre-1970)",
str_detect(type, "> 1970") ~ "Apartments (post-1970)",
str_detect(type, "Tussenwoning") ~ "Terraced house",
str_detect(type, "Hoekwoning") ~ "Corner house",
str_detect(type, "Vrijstaand") ~ "Detached house",
str_detect(type, "2-onder-1-kap") ~ "Semi-detached house"
),
type = factor(type, levels = c(
"Apartments (pre-1970)", "Apartments (post-1970)",
"Terraced house", "Corner house", "Detached house",
"Semi-detached house", "Total"
))
) |>
glimpse()
Rows: 259
Columns: 16
$ type <fct> Terraced house, Terraced house, Terraced house,…
$ date <date> 2012-03-01, 2012-06-01, 2012-09-01, 2012-12-01…
$ asking_price <dbl> 298444, 269778, 241000, 270500, 354056, 305611,…
$ transaction_price <dbl> 278911, 252278, 230111, 256667, 334472, 281528,…
$ price_per_m2 <dbl> 2492, 2370, 2308, 2291, 2648, 2203, 2412, 2344,…
$ n_offered <dbl> 655, 732, 717, 717, 676, 732, 715, 617, 534, 57…
$ n_sold <dbl> 99, 119, 107, 153, 93, 93, 123, 148, 121, 178, …
$ mortgage_months <dbl> 126, 103, 85, 125, 147, 113, 135, 85, 121, 57, …
$ tightness_index <dbl> 19.8, 18.5, 20.1, 14.1, 21.8, 23.6, 17.4, 12.5,…
$ quarter <dbl> 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4,…
$ year <dbl> 2012, 2012, 2012, 2012, 2013, 2013, 2013, 2013,…
$ diff_ask_paid <dbl> -19533, -17500, -10889, -13833, -19584, -24083,…
$ diff_ask_paid_perc <dbl> -0.065449465, -0.064868151, -0.045182573, -0.05…
$ diff_offered_sold <dbl> 556, 613, 610, 564, 583, 639, 592, 469, 413, 39…
$ diff_offered_sold_perc <dbl> 0.848854962, 0.837431694, 0.850767085, 0.786610…
$ perc_sold <dbl> 0.1511450, 0.1625683, 0.1492329, 0.2133891, 0.1…
The first thing that seems interesting to do is to plot the percentage difference between the asking price and the price paid. This will give us an indication of the trend in overpaying on different types of properties. Let’s use a simple line graph to visualize the percentage overpay.
Show code
colors <- c("#019868", "#9dd292", "#ec0b88", "#651eac", "#e18a1e", "#2b7de5")
data |>
filter(type != "Total") |>
group_by(type) |>
mutate(
n_total = sum(n_sold),
type_label = str_glue(
"{type} (n={format(n_total, big.mark = \".\", decimal.mark = \",\")})"
),
type_label = str_replace(type_label, "\\) \\(", ", ")
) |>
arrange(type) |>
mutate(type_label = factor(type_label)) |>
ggplot(aes(x = date, y = diff_ask_paid_perc, color = type_label)) +
geom_hline(yintercept = 0, color = "grey30", size = 1) +
geom_line(
size = 1.2, alpha = 0.8,
lineend = "round", key_glyph = "point"
) +
labs(
title = "Overbidding has become the new normal",
subtitle = "_Paying as much as 5% over asking price is common the past few years_",
x = NULL,
y = "Percentage difference between\nasking price and price paid",
color = NULL,
caption = "_**Data**: MVA_"
) +
scale_y_continuous(labels = scales::label_percent()) +
scale_color_manual(
values = colors,
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right",
override.aes = list(fill = "transparent", size = 6, alpha = 1)
)
) +
theme(
plot.title = element_textbox(size = 20),
axis.title.y = element_textbox(width = grid::unit(2.5, "in")),
legend.key = element_rect(fill = "transparent", color = "transparent")
)
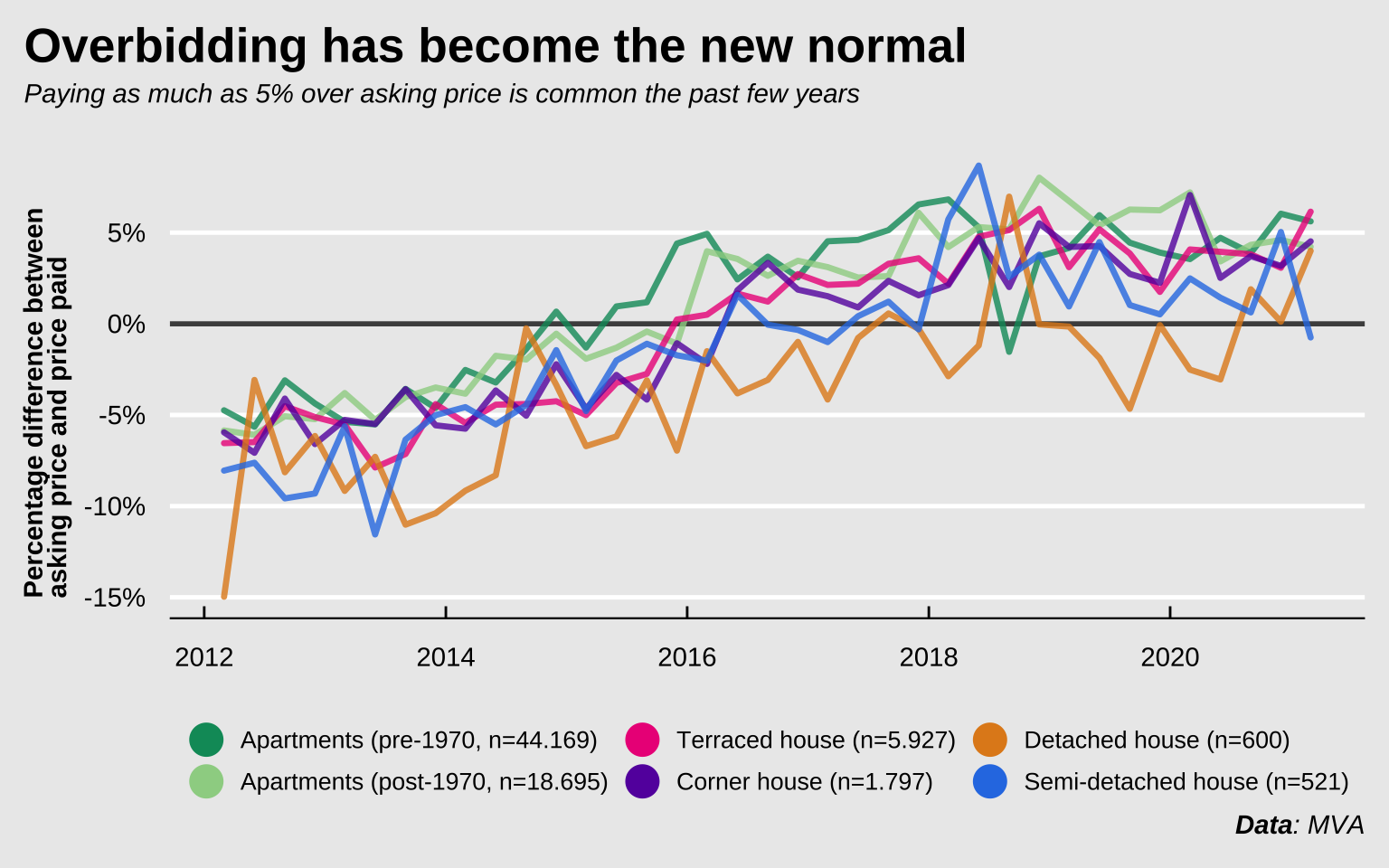
Prior to 2014, most properties in Amsterdam were sold at about 6% below asking price, in the last quarter of 2020, that trend had changed to more than 3.5% above asking. The variance is obviously larger for detached and semi-detached houses, since those are both expensive and scarce in Amsterdam, and are thus also bought and sold less often. The table below shows the stats for the first quarter of 2021. Apart from semi-detached houses, most other properties were sold at 4% over asking or more. The types of properties most accessible to first-time buyers are obviously the apartments. Either the older type in the inner city, or the newer apartments in the suburbs. People buying pre-1970 apartments spent more than €28 000 over the asking price and people buying apartments built after 1970 spent on average more than €18 000 over the asking price.
Show code
data |>
filter(
type != "Total",
date == max(date)
) |>
select(type, diff_ask_paid_perc, diff_ask_paid, transaction_price, n_sold) |>
arrange(-diff_ask_paid_perc) |>
gt() |>
cols_align(columns = "type", align = "left") |>
fmt_percent(columns = "diff_ask_paid_perc") |>
fmt_currency(
columns = "diff_ask_paid", currency = "EUR",
decimals = 0, sep_mark = " "
) |>
fmt_currency(
columns = "transaction_price", currency = "EUR",
decimals = 0, sep_mark = " "
) |>
fmt_number(
columns = "n_sold", sep_mark = " ",
drop_trailing_zeros = TRUE
) |>
cols_label(
type = html("<h5>Property type</h5>"),
diff_ask_paid_perc = html("<h5>Percentage overpay</h5>"),
diff_ask_paid = html("<h5>Mean overpay</h5>"),
transaction_price = html("<h5>Mean transaction price</h5>"),
n_sold = html("<h5>Number of properties<br>sold in period</h5>")
) |>
tab_header(
title = html("<h3 style='margin-bottom: 0'>Difference between<br>asking price and price paid</h3>"),
subtitle = html("<h4 style='margin-top: 0'><em>Data from the first quarter of 2021</em></h4>")
) |>
tab_source_note(source_note = md("_**Data**: MVA_")) |>
tab_options(table.background.color = "#EBEBEB") |>
gtsave("overpay-table.png", expand = 0)
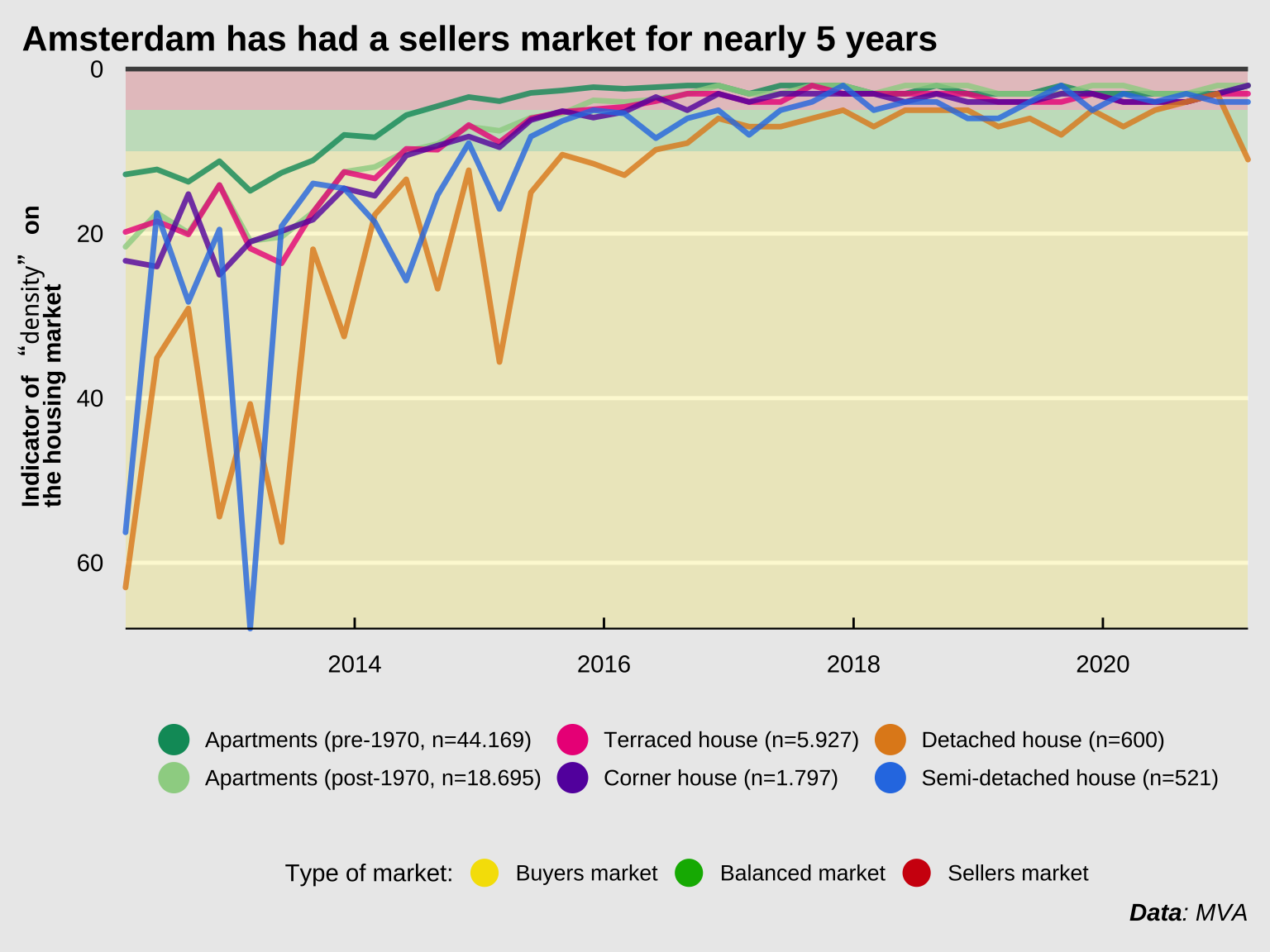
What contributed to this price increase? A simple supply-and-demand plays a part. The figure below shows the “tightness index” (Dutch: “krapte indicator”) over time. This number represents the number of choices a potential buyer has. This number is calculated per quarter by dividing the number of properties on the market halfway through the quarter divided by the number of transactions over the entire quarter. This number is then multiplied by 3 to correct for the fact that the number is calculated per quarter instead of per month. When the “tightness index” is below 5, it’s considered a “sellers market” (source: NVM). A larger number is good for buyers, a smaller number is good for sellers. In the first quarter of 2021, the number was exactly 2. It varies a bit per property type, but for apartments specifically it hasn’t been higher than 3 since 2016. This means that first-time buyers often don’t have a choice between more than 2 or 3 apartments per month. I tried to find some data on how many people currently are interested in buying a home in Amsterdam, but I couldn’t find anything solid. There’s only anecdotal evidence from viewings where within a year, the number of people interested in viewing a property has increased to 80 in 2020, compared to about 55 a year earlier (source: Parool).
Show code
data |>
filter(type != "Total") |>
group_by(type) |>
mutate(
n_total = sum(n_sold),
type_label = str_glue(
"{type} (n={format(n_total, big.mark = \".\", decimal.mark = \",\")})"
),
type_label = str_replace(type_label, "\\) \\(", ", ")
) |>
arrange(type) |>
mutate(type_label = factor(type_label)) |>
ggplot(aes(x = date, y = tightness_index, color = type_label)) +
geom_rect(
data = tibble(),
aes(
xmin = as.Date(-Inf), xmax = as.Date(Inf),
ymin = c(0, 5, 10), ymax = c(5, 10, Inf),
fill = c("Sellers market", "Balanced market", "Buyers market")
),
color = "transparent", alpha = 0.2, key_glyph = "point", inherit.aes = FALSE
) +
geom_hline(yintercept = 0, color = "grey30", size = 1) +
geom_line(size = 1.2, alpha = 0.8, lineend = "round", key_glyph = "point") +
labs(
title = "Amsterdam has had a sellers market for nearly 5 years",
x = NULL,
y = "Indicator of _\"density\"_ on the housing market",
color = NULL,
fill = "Type of market:",
caption = "_**Data**: MVA_"
) +
scale_x_date(expand = c(0, 0)) +
scale_y_continuous(trans = "reverse", expand = c(0, 0)) +
scale_color_manual(
values = colors,
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right", order = 1,
override.aes = list(fill = "transparent", size = 6, alpha = 1)
)
) +
scale_fill_manual(
values = c("#F5E000", "#00B300", "#D1000E"),
limits = c("Buyers market", "Balanced market", "Sellers market"),
guide = guide_legend(
order = 2,
override.aes = list(
shape = 21, size = 6,
alpha = 1, stroke = 0
)
)
) +
coord_cartesian(clip = "off") +
theme(
plot.title = element_textbox(size = 16),
plot.subtitle = element_textbox(size = 10),
axis.title.y = element_textbox(
orientation = "left-rotated",
width = grid::unit(2, "in")
),
legend.key = element_rect(fill = "transparent")
)
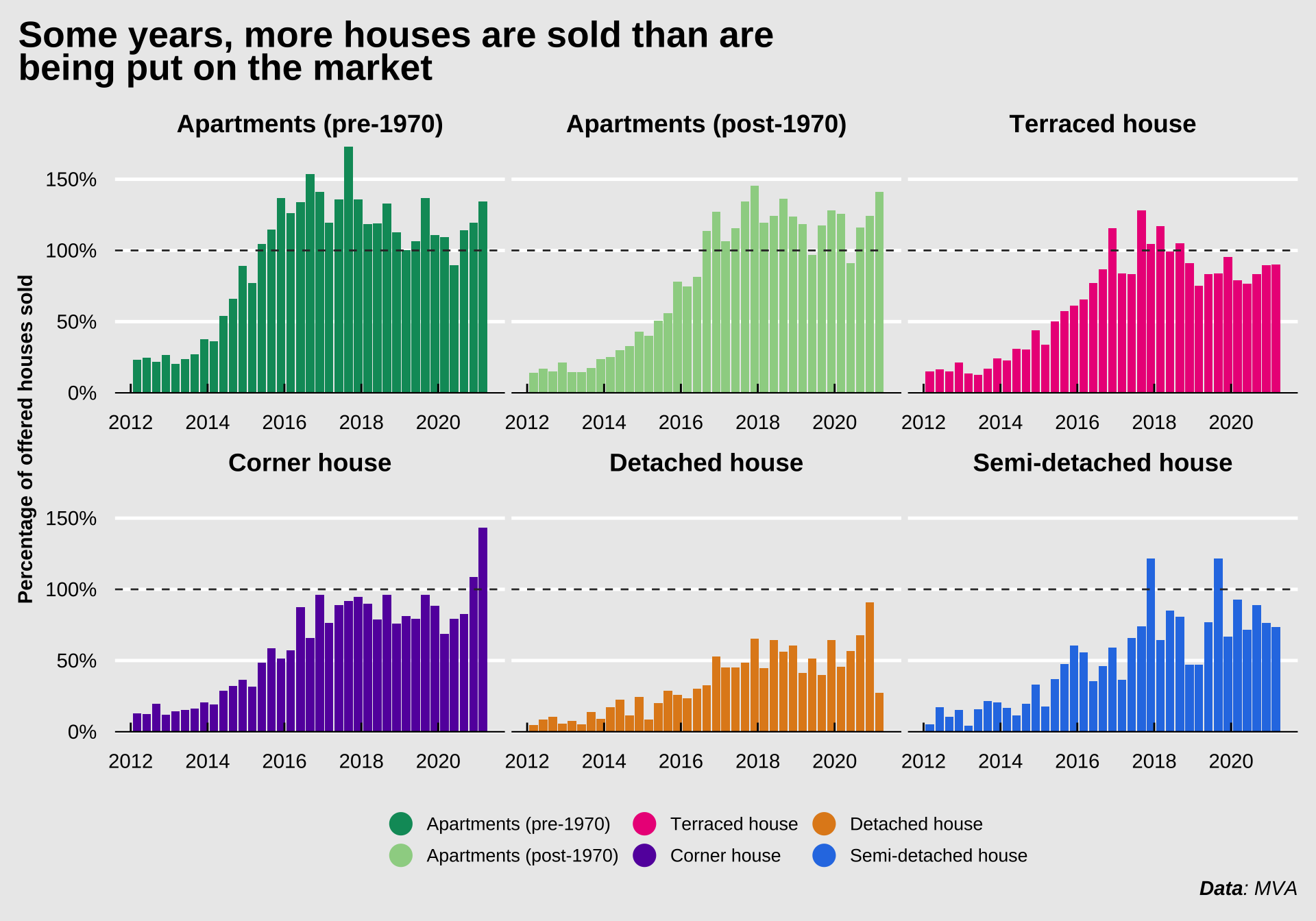
So, there’s a lot of competition among buyers, and people looking to sell their houses can expect to be paid more than they anticipated. Dozens of buyers compete for the same properties, driving up the price. The figure below shows the percentage of properties sold compared to the number of properties offered. It’s clear that after the 2008 housing bubble crisis, the housing market was still recovering in 2012 and 2013. However, since 2016, more apartments were sold than were put on the market. This means that the number of properties available for the growing number of people wanting to move to Amsterdam is decreasing. This decreases supply in a time with increasing demand, thus pushing the prices higher twice over.
A new phenomenon that entered the scene a little while ago may indicate how skewed the market is. People wanting to buy a house in a certain neighborhood will put notes and letters in the mailboxes of people living in that area saying “Nice house! Are you interested in selling it to me?”. This is now not an uncommon strategy to find a house. Some people living in popular neighborshoods are inundated with notes from agencies facilitating these practices. See also a news item by RTL
Show code
data |>
filter(type != "Total") |>
ggplot(aes(x = date, y = perc_sold, fill = type)) +
geom_col(key_glyph = "point") +
geom_hline(yintercept = 1, linetype = "dashed", color = "grey20") +
labs(
title = "Some years, more houses are sold than are being put on the market",
x = NULL,
y = "Percentage of offered houses sold",
fill = NULL,
caption = "_**Data**: MVA_"
) +
coord_cartesian(clip = "off") +
scale_y_continuous(
labels = scales::label_percent(),
expand = c(0, NA), n.breaks = 4
) +
scale_fill_manual(
values = colors,
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right",
override.aes = list(shape = 21, size = 6, alpha = 1, stroke = 0)
)
) +
theme(
plot.title = element_textbox(
size = 20,
width = grid::unit(6, "in")
),
plot.subtitle = element_textbox(size = 10),
strip.text.x = element_markdown(
face = "bold",
padding = margin(10, 0, 5, 0, "pt")
),
strip.background = element_rect(fill = "transparent"),
legend.key = element_rect(fill = "transparent")
) +
facet_wrap(~type, strip.position = "top", scales = "free_x")
This adds fuel to the fire. I guess I’m trying to show that there are a number of factors stacked against young buyers. Any money you have saved up you need to spend to outbid the massive competition. The massive competition means buyers only have a handful of feasible options. Again, because of the massive competition, the chance they actually get to buy one of those options is low. The number of options is not steady either, the number properties sold has overtaken the number of properties being put on the market. There is a dwindling reserve of properties. Combine this with more and more young people wanting to move to the bigger cities and you have a perfect cocktail for a congested housing market. Building new properties can counteract this, but over the last years the Netherlands has actually slowed building new properties.
Show code
decades <- tibble(
x1 = seq(1920, 2020, 10),
x2 = x1 + 10
) |>
slice(seq(1, 1e2, 2)) |>
filter(x2 < 2030)
hist_data_homes <- cbsodataR::cbs_get_data("82235NED") |>
janitor::clean_names() |>
rename(stock_end = eindstand_voorraad_8) |>
mutate(
year = parse_number(perioden),
stock_end = stock_end * 1e3,
diff = stock_end - lag(stock_end)
)
total_hist_plot <- hist_data_homes |>
ggplot(aes(x = year, y = stock_end)) +
geom_rect(
data = tibble(), aes(xmin = 1940.01, xmax = 1945, ymin = -Inf, ymax = Inf),
fill = "red", alpha = 0.2, inherit.aes = FALSE
) +
geom_text(
data = tibble(),
aes(x = 1942.5, y = max(hist_data_homes$stock_end, na.rm = TRUE)),
label = "WWII", fontface = "bold", family = "nunito-sans",
vjust = 0, size = 3, inherit.aes = FALSE
) +
geom_rect(
data = decades, aes(xmin = x1, xmax = x2, ymin = -Inf, ymax = Inf),
fill = "grey30", alpha = 0.2, color = "transparent", inherit.aes = FALSE
) +
geom_line(color = "darkred", size = 1.5, lineend = "round") +
labs(
x = NULL,
y = "Total number of homes"
) +
scale_x_continuous(
expand = c(0, 0),
breaks = c(decades$x1, decades$x2, 2020)
) +
scale_y_continuous(labels = scales::label_number()) +
coord_cartesian(clip = "off")
diff_hist_plot <- hist_data_homes |>
ggplot(aes(x = year, y = diff)) +
geom_hline(yintercept = 0.5, color = "grey30", size = 1) +
geom_rect(
data = tibble(), aes(xmin = 1940.01, xmax = 1945, ymin = -Inf, ymax = Inf),
fill = "red", alpha = 0.2, inherit.aes = FALSE
) +
geom_text(
data = tibble(), aes(
x = 1942.5,
y = max(hist_data_homes$diff, na.rm = TRUE),
vjust = 0, label = "WWII"
),
size = 3, fontface = "bold",
family = "nunito-sans", inherit.aes = FALSE
) +
geom_rect(
data = decades, aes(xmin = x1, xmax = x2, ymin = -Inf, ymax = Inf),
fill = "grey30", alpha = 0.2, color = "transparent", inherit.aes = FALSE
) +
geom_line(color = "grey30", alpha = 0.5, size = 1.5, lineend = "round") +
geom_smooth(color = "darkred", size = 1.5, se = FALSE) +
labs(
x = NULL,
y = "Net homes added per year"
) +
scale_x_continuous(
expand = c(0, 0),
breaks = c(decades$x1, decades$x2, 2020)
) +
scale_y_continuous(labels = scales::label_number_auto()) +
coord_cartesian(clip = "off")
total_hist_plot / diff_hist_plot +
plot_annotation(
title = "Number of houses available",
subtitle = "Data covers development in the Netherlands nationwide",
caption = "**Data**: CBS"
) &
theme(plot.title = element_textbox(size = 20))
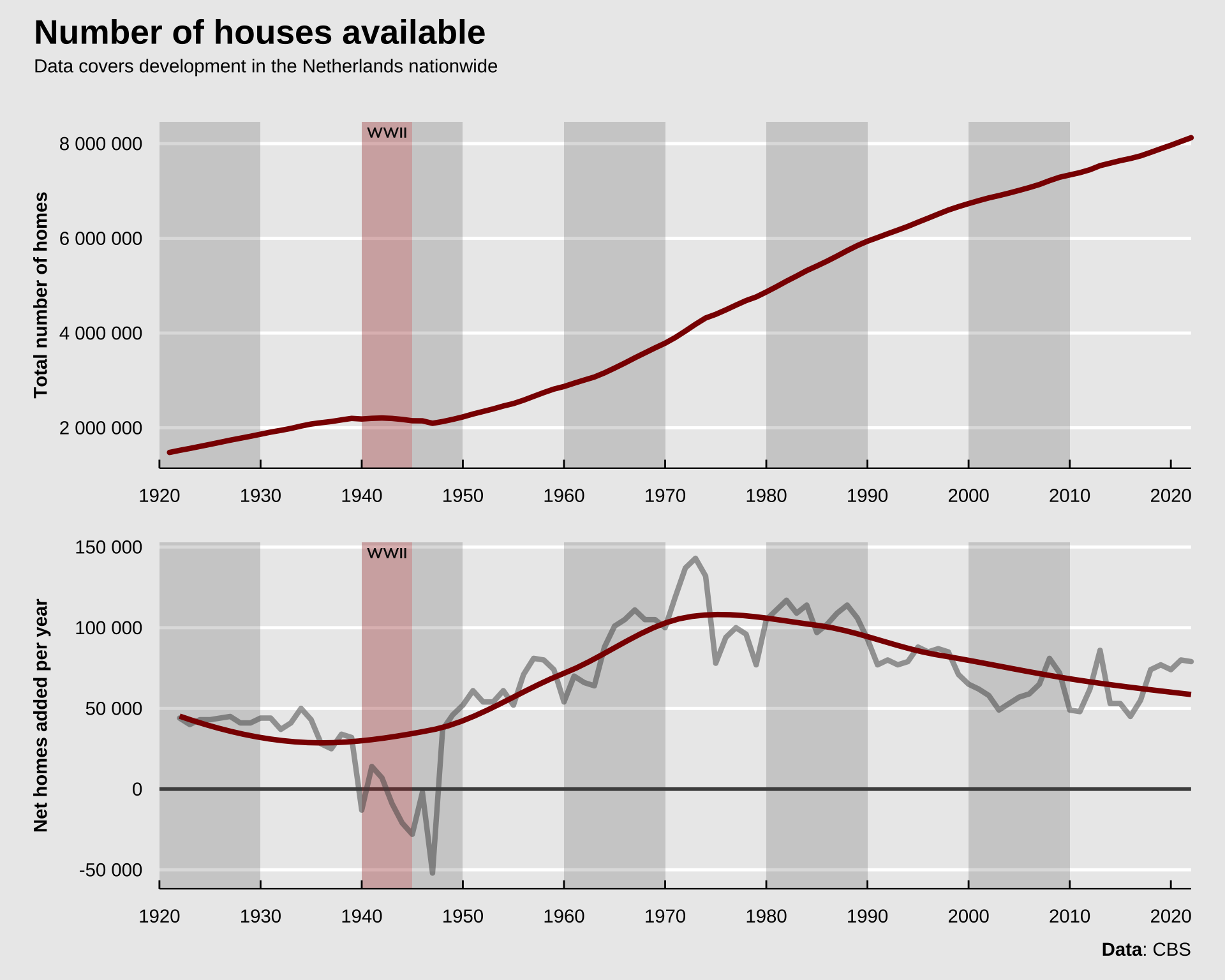
The figure displays data from from the CBS through the {cbsodataR} package. It shows an increase in the number of homes after the second World War in the 50s and the 60s. Since around 1975 there’s been a decline in the net number of new houses added year-over-year. This while demand hasn’t decreased in the same period.
It’s also important to mention that between the 60s and 70s, the Netherlands started building entire cities from scratch on newly-reclaimed land from the sea. The province of Flevoland is currently home to about 415 000 people, and until the early 50s this province was non-existent, the current land was at the bottom of a bay of the North sea (called the Zuiderzee or “Southern Sea” in English). Other than a general enthusiasm for building, I think this contributed considerably to the increase in the number of homes added in the 60s and 70s. This new province has good access to Amsterdam, and if it weren’t for this new piece of land, the shortage might have peaked earlier.
But that’s not all, there’s a few other features that contribute to the gridlock. See, not only young people are on the market to buy apartments in Amsterdam. There’s a thriving market for investors looking to take advantage of the rising prices in the Amsterdam housing market (source: Algemeen Dagblad). According to the Dutch central bank, about 1 in 5 properties are sold to investors, who are mostly looking to convert it to a rental property or flip it for a profit. I couldn’t find the data the Dutch central bank relied on, but I found something else. The Central Bureau for Statistics collects data on the number of “mutations” among properties. The “mutation” in this case refers to the change of purpose of a property, e.g. if a house meant for sale is bought and then transformed to a rental property by either private individuals or corporations, or vice versa. I collected this data from the governmental yearly report on the housing market of 2020 ("Staat van de Woningmarkt - Jaarrapportage 2020", link). Instead of per quarter, this data is reported per year. Unfortunately, the data on housing mutations in the report (from 2020 mind you) only goes until 2017. It’s important to note that these numbers are country-wide, not specific for Amsterdam. That means there could be some other factors in play. Many of these trends are present across the country, but they’re massively amplified in the larger cities. The data was contained in a pdf that wasn’t easily machine-readable, so I had to manually copy the numbers into a tibble, which was great…
Show code
house_mutations_in <- tribble(
~year, ~buy_to_rent_corp, ~buy_to_rent_other, ~rent_corp_to_buy,
~rent_corp_to_rent_other, ~rent_other_to_buy, ~rent_other_to_rent_corp,
2012, 900, 58000, 14600, 5500, 50600, 4900,
2013, 800, 62200, 15200, 11500, 50900, 6000,
2014, 1000, 62200, 15400, 9300, 59900, 39000,
2015, 1200, 63700, 12600, 20000, 61300, 7300,
2016, 1300, 77900, 8300, 5300, 62400, 4900,
2017, 1600, 98900, 6400, 11000, 7300, 9000
)
house_mutations <- house_mutations_in |>
pivot_longer(
cols = -year,
names_to = "mutation", values_to = "n_mutations"
) |>
mutate(
from = str_extract(mutation, "(.*?)_to"),
from = str_remove_all(from, "_to"),
to = str_extract(mutation, "to_(.*?)$"),
to = str_remove_all(to, "to_")
) |>
group_by(year) |>
mutate(
total_mutations = sum(n_mutations),
perc_mutations = n_mutations / total_mutations,
across(c(from, to), ~ case_when(
str_detect(.x, "buy") ~ "buy",
str_detect(.x, "rent_corp") ~ "rent (corporation)",
str_detect(.x, "rent_other") ~ "rent (other)"
)),
mutation_label = str_glue("From {from} to {to}")
) |>
ungroup()
So not every year there’s the same number of “mutations” (transformations of purpose). That’s I thought I’d display this data in two different plots, one with the raw values per year, and one with the percentage-wise deconstruction per year. Now obviously, first-time buyers don’t care about the percentage houses being taken of the market and being transformed into rental properties, they care about the total number. However, I do think showing the percentage-wise plot makes the trend a bit more clearly.
Show code
mutations_n_plot <- house_mutations |>
arrange(from, to) |>
mutate(mutation_label = fct_inorder(mutation_label)) |>
ggplot(aes(
x = year, y = n_mutations,
alluvium = mutation_label, fill = mutation_label
)) +
geom_point(shape = 21, color = "transparent", size = NA) +
ggalluvial::geom_flow(width = 0, show.legend = FALSE) +
labs(
x = NULL,
y = "Number of mutations",
fill = NULL
) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(
labels = scales::label_number_auto(),
expand = c(0, 0)
) +
scale_fill_manual(
values = rev(colors),
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right",
override.aes = list(
color = "transparent", size = 6,
alpha = 1, stroke = 0
)
)
) +
theme(legend.key = element_rect(fill = "transparent"))
mutations_perc_plot <- house_mutations |>
arrange(from, to) |>
mutate(mutation_label = fct_inorder(mutation_label)) |>
ggplot(aes(
x = year, y = perc_mutations,
alluvium = mutation_label, fill = mutation_label
)) +
geom_point(shape = 21, color = "transparent", size = NA) +
ggalluvial::geom_flow(width = 0, show.legend = FALSE) +
labs(
x = NULL,
y = "Percentage of total mutations per quarter",
fill = NULL
) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(labels = scales::label_percent(), expand = c(0, 0)) +
scale_fill_manual(
values = rev(colors),
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right",
override.aes = list(
color = "transparent", size = 6,
alpha = 1, stroke = 0
)
)
) +
theme(
axis.title.y = element_textbox(width = grid::unit(2, "in")),
legend.key = element_rect(fill = "transparent")
)
mutations_n_plot / mutations_perc_plot +
plot_annotation(
title = "Shift to a renters market",
subtitle = "_A lot more houses meant for sale are being transformed into rental properties than vice versa_",
caption = "_**Data**: CBS_"
) +
plot_layout(guides = "collect") &
theme(plot.title = element_textbox(size = 20))
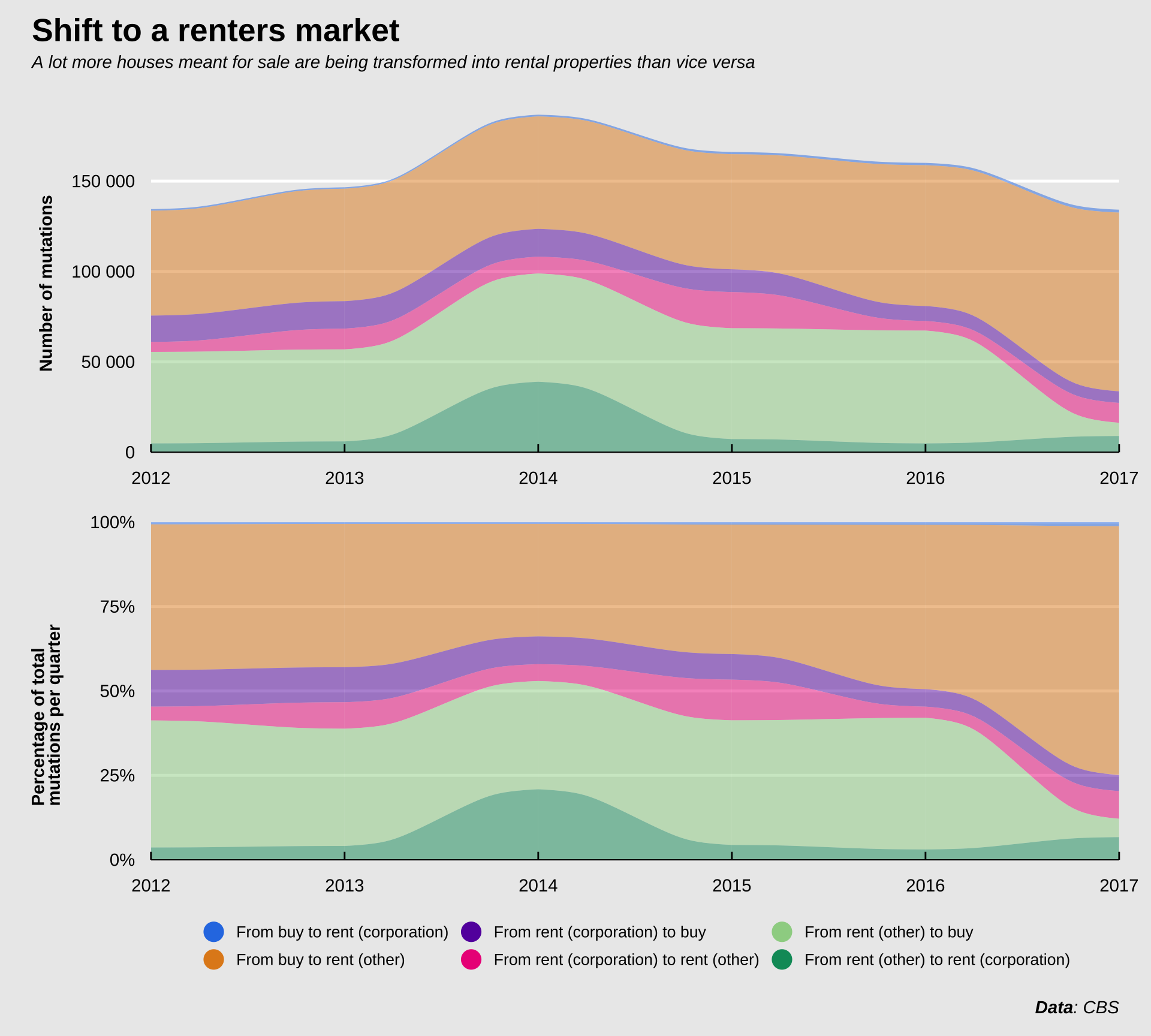
The total number of mutations has hovered around 150 000 since 2012. There was a bump in 2014 when about 40 000 properties were changed from “rent (other)” to “rent (corporation)”. The label “rent (other)” includes mostly private rentals or government-run rental properties, I think. I suspect that in 2014 one of those government-run rental agencies was privatized, causing the bump. The number of mutations from type to type has been fairly consistent until 2016. After 2016 there was a massive drop in the number of private rental properties being put up for sale, and a massive increase in the number of properties meant for sale being added to the private rental market. My guess is that this increase represents investors getting more and more involved in buying up properties and renting them out. Whereas in e.g. 2012, there was about an equal number of properties exchanged between the private rental market and the sale market, this balance is now heavily skewed. Relating this to the previous figures, where we showed that the number of houses sold exceeds the number of houses being put on the market, this also means that among those houses sold, a large number isn’t kept in the sale market but rather added to the rental market.
We can look at the net number of houses added to the rental market by adding up the different mutations. Again, prior to 2016, there were slightly more houses added to the sale market than the rental market, but after 2016, this number skyrocketed in favor of the rental market, when tens of thousands of properties were withdrawn from the sale market. Unfortunately I couldn’t find any data since then to see if 2017 happened to be an outlier and if this number corrected to a more reasonable number since then.
Show code
net_house_mutations <- house_mutations |>
mutate(across(c(from, to), ~ case_when(
str_detect(.x, "rent") ~ "rent",
str_detect(.x, "buy") ~ "buy"
))) |>
group_by(year) |>
filter(from != to) |>
mutate(total_mutations = sum(n_mutations)) |>
group_by(year, from, to) |>
summarise(
n_mutations = sum(n_mutations),
total_mutations = first(total_mutations)
) |>
pivot_wider(
id_cols = c(year, total_mutations),
names_from = c(from, to),
values_from = n_mutations,
names_sep = "_to_"
) |>
mutate(
net_buy_to_rent = buy_to_rent - rent_to_buy,
perc_buy_to_rent = buy_to_rent / total_mutations
)
net_mutation_plot <- net_house_mutations |>
ggplot(aes(x = year, y = net_buy_to_rent)) +
geom_hline(yintercept = 0, color = "grey30", size = 1) +
geom_line(color = "darkred", size = 1.5, lineend = "round") +
labs(
x = NULL,
y = "**Net number of properties changed from properties meant for sale to rental properties**"
) +
scale_y_continuous(
labels = scales::label_number_auto(),
limits = c(-3e4, NA), n.breaks = 5
) +
theme(axis.title.y = element_textbox(width = grid::unit(3.5, "in")))
perc_mutation_plot <- net_house_mutations |>
ggplot(aes(x = year, y = perc_buy_to_rent)) +
geom_hline(yintercept = 0.5, color = "grey30", size = 1) +
geom_line(color = "darkred", size = 1.5, lineend = "round") +
labs(
x = NULL,
y = "**Percentage of mutations that changed properties meant for sale to rental properties**"
) +
scale_y_continuous(
labels = scales::label_percent(),
limits = c(0, 1), expand = c(0, 0)
) +
coord_cartesian(clip = "off") +
theme(axis.title.y = element_textbox(width = grid::unit(3.5, "in")))
net_mutation_plot + perc_mutation_plot +
plot_annotation(
title = "Major net shift towards rental market",
subtitle = "_A lot more houses meant for sale are being transformed into rental properties than vice versa_",
caption = "_**Data**: CBS_"
) &
theme(plot.title = element_textbox(size = 20))
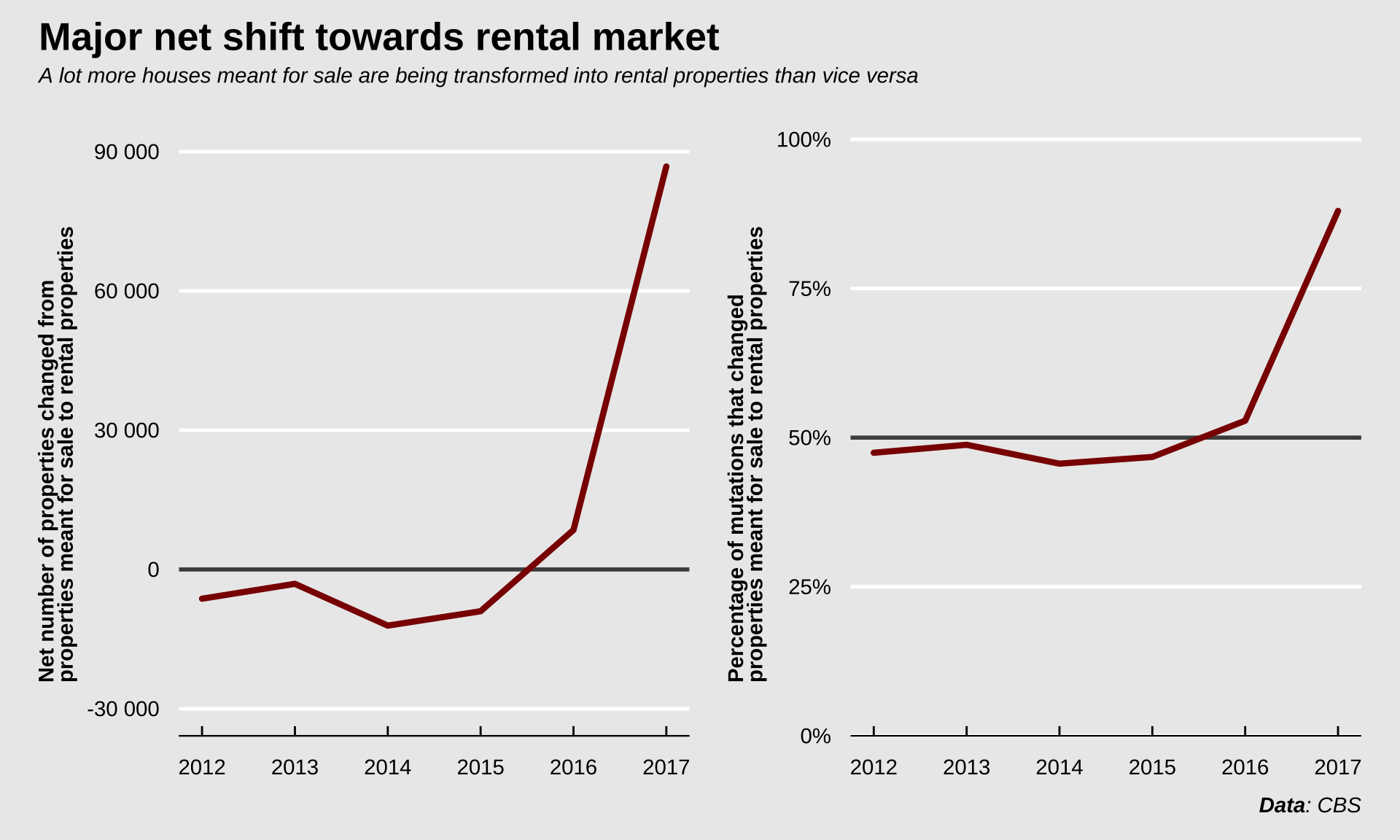
So in 2017 nearly 90 000 houses were mutated from sale to rental properties. In that same year, about 62 000 new homes were built (source: CBS). Not all of those 62 000 homes are meant for sale, a proportion are added to the rental market, but even if all those new homes were meant for sale, the sale market still shrunk due to the (net) ~90 000 properties that were transformed and in that way removed from the sale market.
Show code
house_mutations |>
filter(year == max(year)) |>
select(from, to, n_mutations, perc_mutations) |>
mutate(across(c(from, to), ~ str_to_sentence(.x))) |>
arrange(-perc_mutations) |>
gt() |>
fmt_number(
columns = "n_mutations", sep_mark = " ",
drop_trailing_zeros = TRUE
) |>
fmt_percent(columns = "perc_mutations") |>
grand_summary_rows(
columns = "n_mutations",
fns = list(total = "sum"),
fmt = ~ fmt_number(.),
sep_mark = " ",
drop_trailing_zeros = TRUE
) |>
grand_summary_rows(
columns = "perc_mutations",
fns = list(total = "sum"),
fmt = ~ fmt_percent(.),
missing_text = ""
) |>
cols_label(
from = html("<h5>From</h5>"),
to = html("<h5>To</h5>"),
n_mutations = html("<h5>Number of mutations</h5>"),
perc_mutations = html("<h5>Percentage of total mutations</h5>")
) |>
tab_header(
title = html(
"<h3 style='margin-bottom: 0'>Mutations in the Dutch housing market</h3>"
),
subtitle = html(
"<h4 style='margin-top: 0'><em>Data from the year 2017</em></h4>"
)
) |>
tab_source_note(source_note = md("_**Data**: CBS_")) |>
tab_options(
table.background.color = "#EBEBEB",
grand_summary_row.text_transform = "capitalize"
) |>
gtsave("mutations-table.png", expand = 0)
So what’s the result of all these phenomena? The figure below shows the housing price index for Amsterdam. The first quarter of 2012 was taken as the reference point (100%). In the past 8(!) years, properties had on average nearly doubled in price.
Show code
asking_start <- data |>
filter(
type != "Total",
date == min(date)
) |>
rename(asking_start = asking_price) |>
select(type, asking_start)
data_asking_index <- data |>
filter(type != "Total") |>
left_join(asking_start) |>
mutate(asking_index = asking_price / asking_start)
data_asking_index |>
ggplot(aes(x = date, y = asking_index, color = type, group = type)) +
geom_line(size = 2, alpha = 0.15, lineend = "round", show.legend = FALSE) +
geom_smooth(se = FALSE, show.legend = FALSE) +
geom_point(size = NA) +
labs(
title = "Price development over the past decade",
subtitle = "_On average, properties doubled in value since 2012_",
x = NULL,
y = "Price development relative to early 2012",
color = NULL,
caption = "_**Data**: MVA_"
) +
scale_y_continuous(labels = scales::label_percent()) +
scale_color_manual(
values = colors,
guide = guide_legend(
title.position = "top", title.hjust = 0.5, nrow = 2,
label.position = "right",
override.aes = list(fill = "transparent", size = 6, alpha = 1)
)
) +
theme(
plot.title = element_textbox(size = 20),
axis.title.y = element_textbox(width = grid::unit(2.5, "in")),
legend.key = element_rect(fill = "transparent", color = "transparent")
)
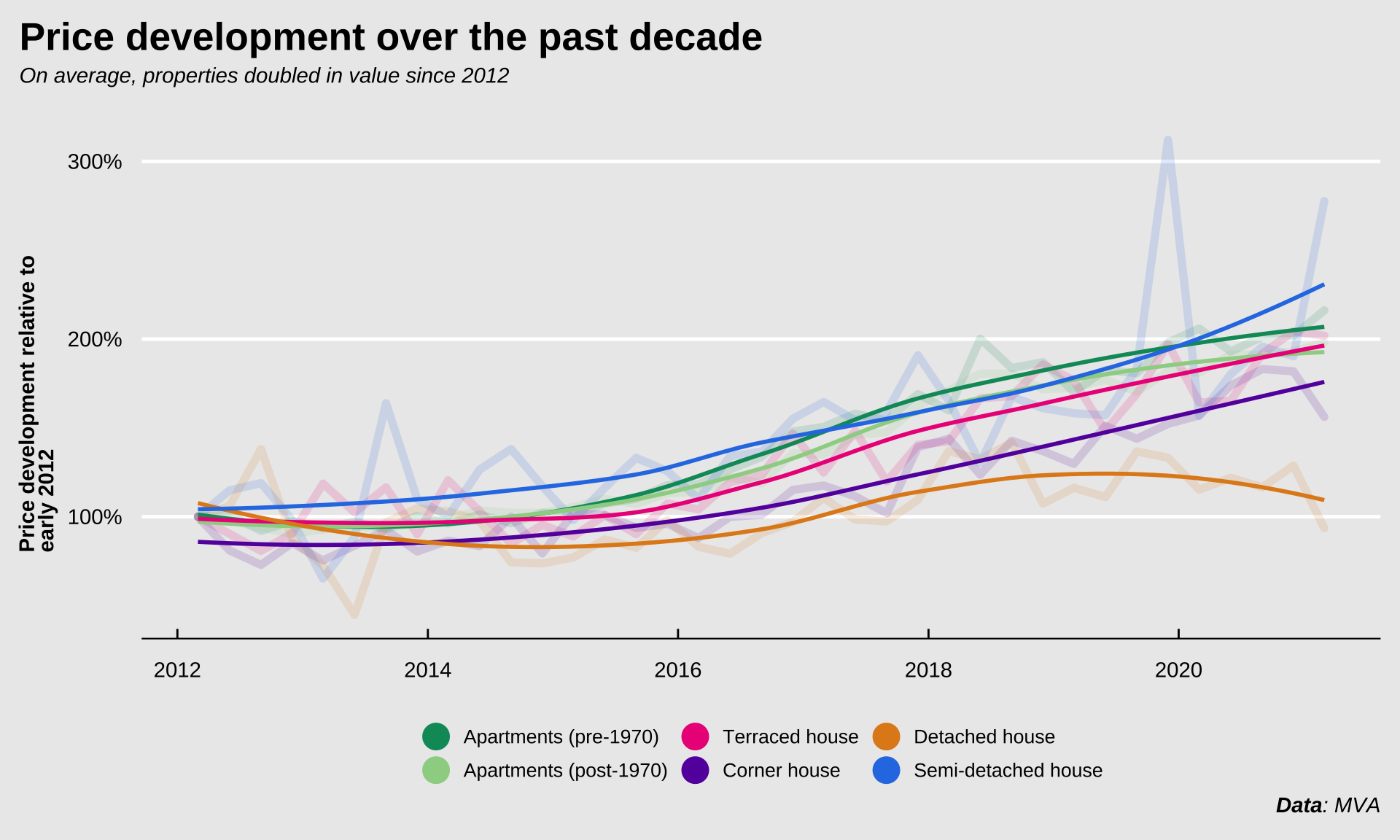
Adjusted for the number of properties offered, the average asking price in Amsterdam has increased by 107%. That means that prices since 2012 have (on average) roughly doubled. For apartments, this increase was 110%. So young people wanting to buy a house in Amsterdam need to bring nearly twice as much money to the table as they did just a decade ago. The money they saved and the salaries they earned have by no means kept up with the increasing price though.
I cannot know this for sure, because the data I presented here doesn’t contain the answer, but perhaps these factors combined play a role in the financial uncertainty that millenials experience. How do we fix it? I’m not sure. This is a really complicated issue. But a few things might (in my opinion) help:
Build more (sustainable) durable houses
Prohibit sale of properties to individuals who don’t plan to live there themselves for at least 2 or 3 years
Increase transparency when buying or selling a house through mandatory public offerings to prevent scooping by investors
Rent control to make “mutating” houses less profitable
Increased socialized housing for poor and low-income families
Perhaps if we implement a few of these strategies we can make the housing market a little fairer and perhaps ensure that future generations will have the same opportunities current home-owners have.
EDIT (2021-12-03): Reintroduce the code to wrangle the data, generate the figures and tables etc. to the main document and put the code inside unfoldable tags to make it easier to see the code associated with a particular step while maintaining legibility.